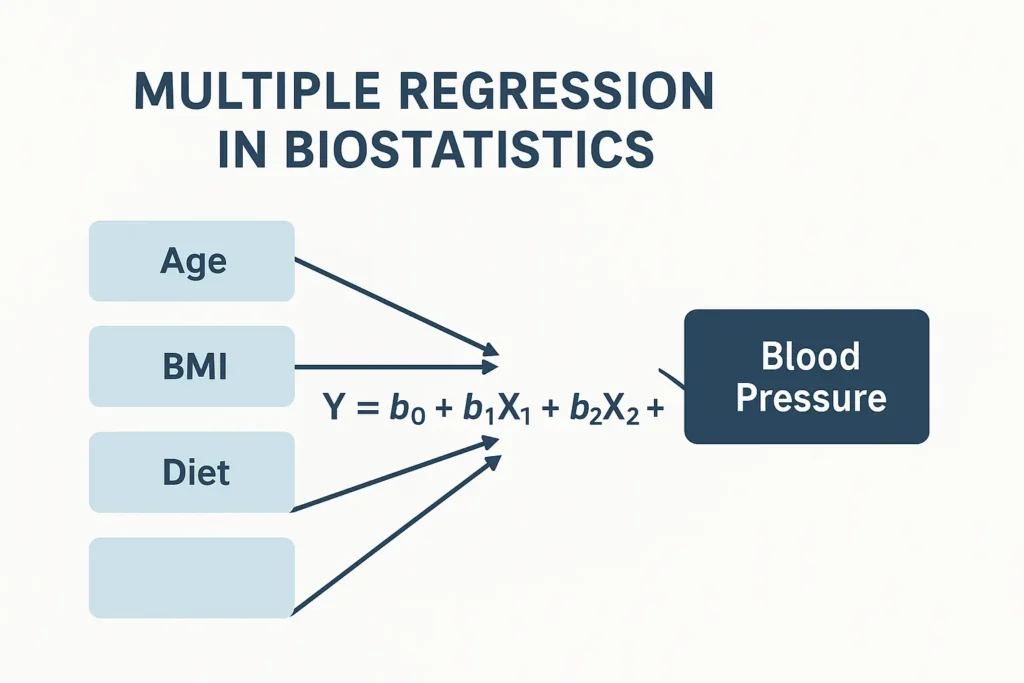
Introduction
The integration of machine learning (ML) into biostatistics marks a transformative era in biological and medical sciences. Biostatistics has long been the foundation of designing experiments, analyzing biological data, and drawing reliable conclusions. However, as datasets grow exponentially due to advancements in genomics, imaging, and clinical trials, traditional statistical methods often struggle to handle such complexity.
Machine learning offers a powerful solution by enabling computers to learn patterns from data and make predictions without being explicitly programmed. In biostatistics, ML algorithms such as random forests, support vector machines, and neural networks are being used to analyze massive biological datasets, predict disease outcomes, and identify risk factors with unprecedented precision.
This article explores how machine learning complements traditional biostatistics, highlights its major applications, explains key algorithms, and discusses future directions in the field. Whether you’re a researcher, student, or professional in life sciences, understanding ML’s role in biostatistics is essential to stay ahead in modern biological data analysis.
What is Machine Learning in Biostatistics?
Machine Learning (ML) in biostatistics refers to the use of computational algorithms to automatically analyze biological data, detect patterns, and make predictions. While traditional biostatistics relies on predefined models and assumptions (like normality and linearity), ML can adaptively learn from data, even when relationships are non-linear or multidimensional.
Biostatistics ensures that data are correctly collected and interpreted, while machine learning enhances pattern recognition, classification, and prediction capabilities. Together, they form a hybrid analytical approach that strengthens evidence-based biological conclusions.
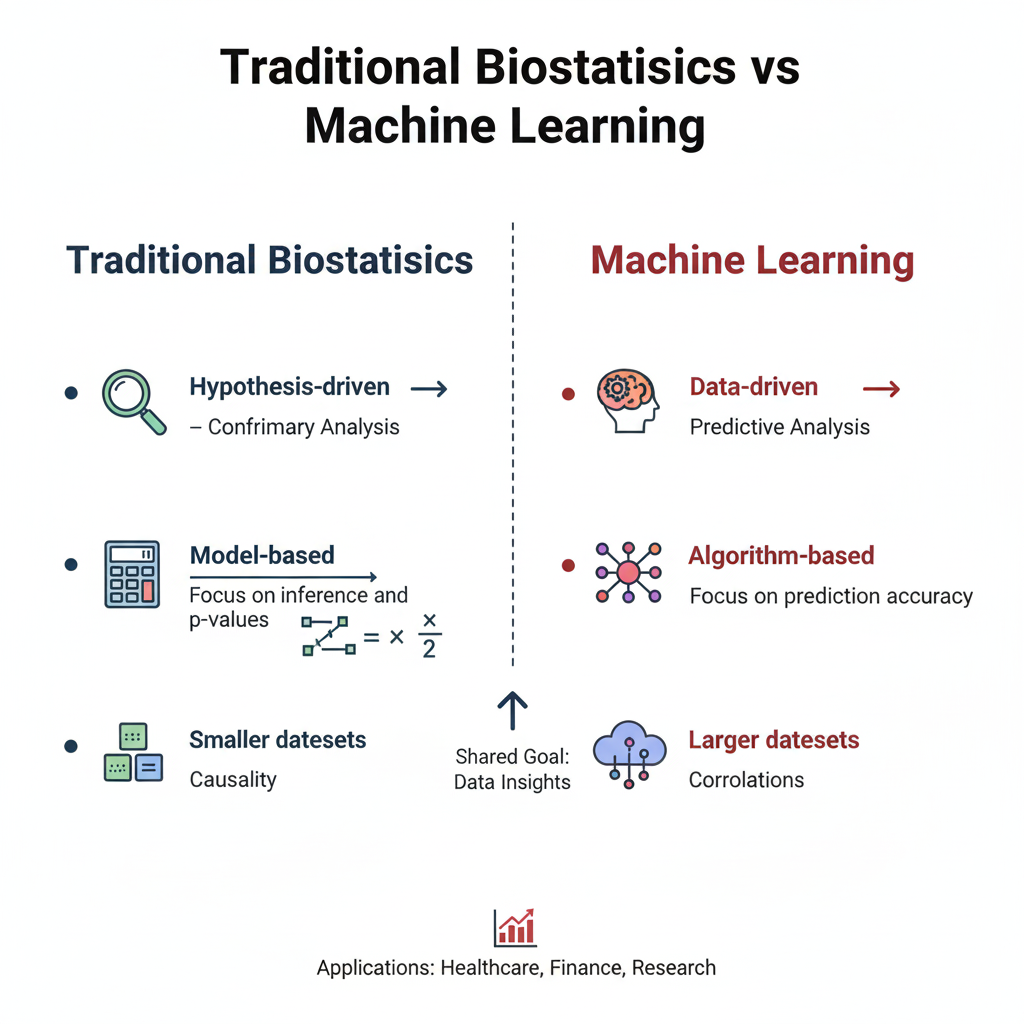
Difference Between Traditional Biostatistics and Machine Learning
| Aspect | Traditional Biostatistics | Machine Learning |
|---|---|---|
| Approach | Model-based, hypothesis-driven | Data-driven, algorithmic |
| Data Size | Small to medium datasets | Large, complex datasets |
| Focus | Parameter estimation and inference | Prediction and pattern recognition |
| Assumptions | Requires normality and independence | Minimal or no strict assumptions |
| Output | P-values, confidence intervals | Predictions, classifications, clusters |
| Examples | t-test, ANOVA, regression | Decision trees, neural networks, SVM |
Importance of Machine Learning in Biostatistics
Handling Big Biological Data
The growth of omics fields (genomics, proteomics, metabolomics) has produced vast datasets. ML helps biostatisticians analyze such high-dimensional data efficiently, revealing relationships that traditional methods might miss.
Improved Disease Prediction
ML algorithms can analyze patient data to predict disease risks, progression, and treatment outcomes. For example, predicting cancer recurrence using gene expression profiles.
Automation of Data Analysis
ML enables automation in tasks like image classification, pattern recognition, and data preprocessing, saving time and minimizing human error.
Enhancing Personalized Medicine
By integrating clinical and genetic data, ML models help create personalized treatment plans for patients, a key goal in precision medicine.
Common Machine Learning Algorithms Used in Biostatistics
1. Decision Trees and Random Forests
Decision trees split data into branches based on predictor variables, while random forests combine multiple trees to reduce overfitting and improve accuracy.
Application Example: Classifying disease types based on biomarkers.
2. Support Vector Machines (SVM)
SVMs find the optimal boundary that separates different classes of data.
Application Example: Differentiating healthy vs. diseased tissue samples in biomedical imaging.
3. Neural Networks
Inspired by the human brain, neural networks can model complex, nonlinear relationships.
Application Example: Predicting patient survival using multidimensional hospital data.
4. K-Means Clustering
Used for unsupervised learning, clustering helps identify hidden groupings in biological data.
Application Example: Grouping patients based on genetic similarity.
5. Logistic Regression (Bridge Between Stats & ML)
A classic biostatistical model that also serves as a foundation for machine learning classification.
Application Example: Predicting disease occurrence (yes/no outcomes).
Applications of Machine Learning in Biostatistics
Genomics and Proteomics
ML identifies key genes or proteins associated with specific diseases, improving biomarker discovery and therapeutic target identification.
Epidemiology
In epidemiological modeling, ML helps predict disease outbreaks, identify risk factors, and simulate intervention strategies.
Clinical Trials
Machine learning assists in patient recruitment, data cleaning, and adaptive trial design, enhancing statistical efficiency.
Medical Imaging
Deep learning models can analyze MRI, CT, or microscopy images to detect anomalies, classify tumors, and assist radiologists.
Drug Discovery
ML accelerates drug design by predicting molecular interactions, toxicity, and bioactivity, reducing experimental costs.
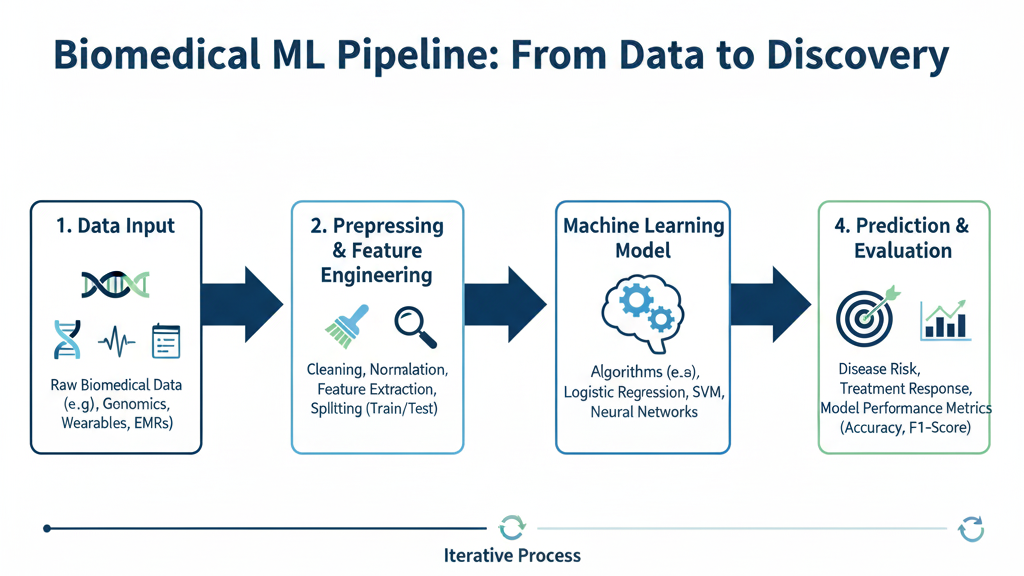
Integration of Machine Learning and Statistical Models
Hybrid Models
Combining statistical methods (like regression) with ML (like random forests) allows for both interpretability and predictive accuracy.
Feature Selection and Validation
ML algorithms often select important predictors automatically. In biostatistics, such variable selection improves model stability and reliability.
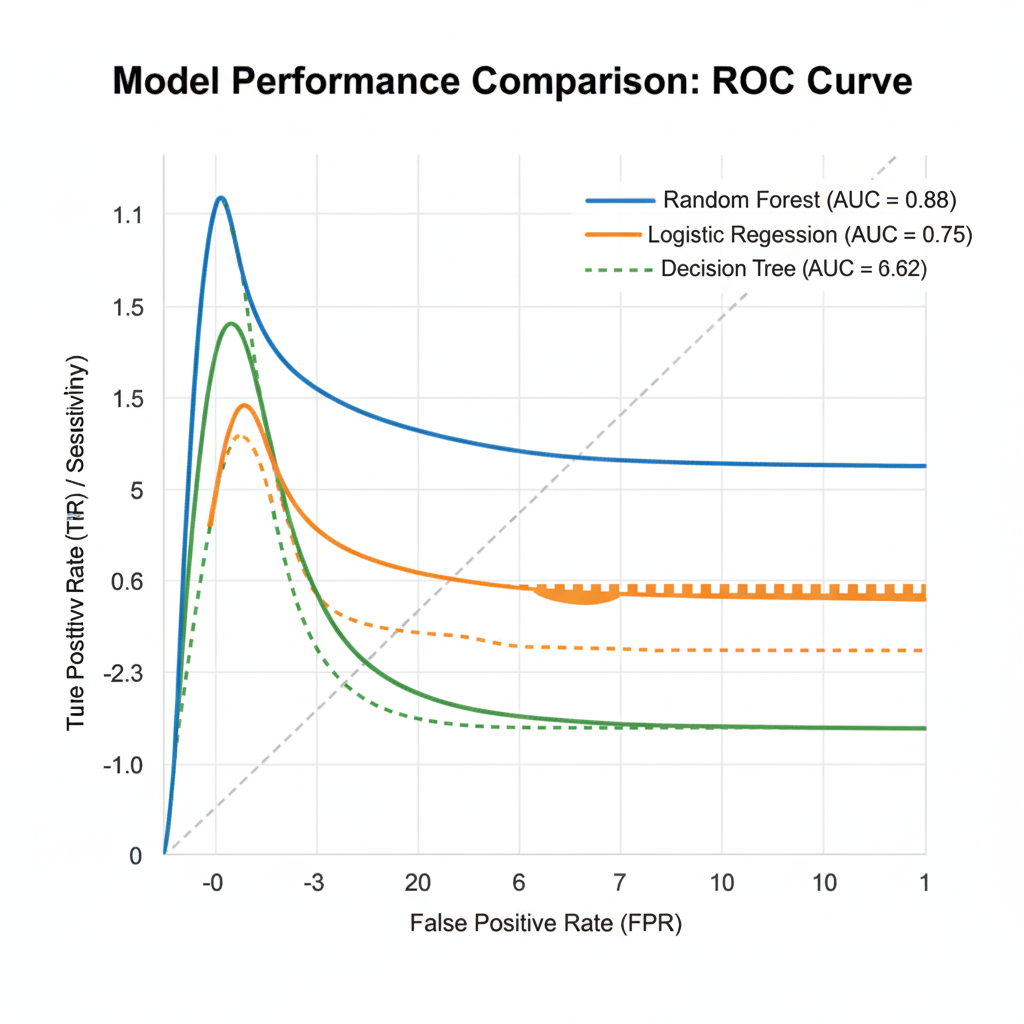
Model Evaluation Metrics
Biostatisticians use statistical tools such as:
- AUC (Area Under the Curve)
- Accuracy and Precision
- Sensitivity and Specificity
- Cross-validation
to evaluate the performance and generalizability of ML models.
Challenges and Limitations
While ML offers exciting opportunities, it also introduces challenges:
- Overfitting: Models that learn noise instead of signal.
- Interpretability: Some ML models (like deep neural networks) act as “black boxes.”
- Data Quality Issues: Missing or biased data can reduce model accuracy.
- Ethical Concerns: Patient privacy and data sharing must follow strict guidelines.
- Integration with Classical Methods: Ensuring ML complements rather than replaces traditional biostatistical inference.
Future of Machine Learning in Biostatistics
The future of biostatistics will be deeply intertwined with machine learning. As computational power increases, algorithms will become more transparent, interpretable, and accessible to non-programmers.
Explainable AI (XAI)
Emerging ML techniques aim to make models more interpretable, allowing biostatisticians to understand why a model made a specific decision.
Integration with Cloud and Big Data
Cloud-based ML tools are revolutionizing data storage and analysis, making large-scale biological computation feasible globally.
Real-Time Biostatistics
ML enables real-time monitoring of patients through wearable sensors and health apps — merging continuous data streams with statistical models.
Education and Collaboration
Future biostatisticians will require hybrid skills in statistics, data science, and programming to navigate this evolving landscape.
How to Learn Machine Learning for Biostatistics
If you’re beginning your journey, here’s a simple roadmap:
| Stage | Focus Area | Recommended Tools |
|---|---|---|
| Beginner | Basic statistics, linear models | Excel, SPSS, R basics |
| Intermediate | ML algorithms, model validation | Python (scikit-learn), R (caret) |
| Advanced | Deep learning, big data handling | TensorFlow, PyTorch, cloud ML tools |
Conclusion
Machine learning has become a game-changer in biostatistics, offering data-driven insights that enhance biological understanding and medical decision-making. While traditional statistical methods remain vital for hypothesis testing and inference, ML extends their power to pattern discovery, classification, and predictive analytics.
The collaboration between biostatisticians and data scientists is driving innovation in areas like personalized medicine, genomics, and public health, paving the way for more accurate, reproducible, and impactful research.
As we move forward, mastering both statistical thinking and machine learning will be essential for every researcher who aims to unlock the full potential of biological data.