Introduction
Modern biological and health sciences generate large, complex datasets involving multiple variables measured simultaneously. In biostatistics, researchers often face the challenge of understanding patterns, relationships, and gradients within such high-dimensional data. Traditional univariate or bivariate methods frequently fall short when dealing with these complexities.
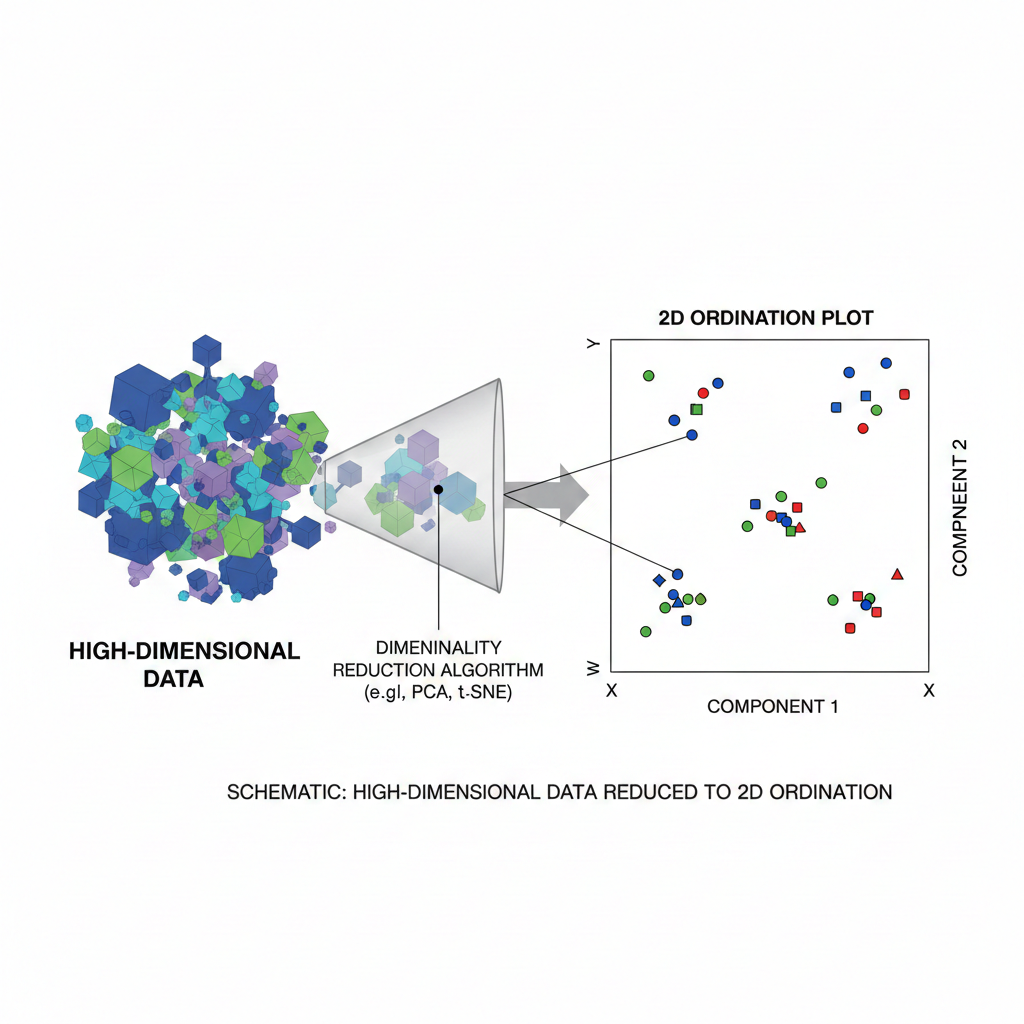
This is where ordination techniques play a crucial role. Ordination methods are multivariate statistical tools used to reduce data dimensionality while preserving the most important information. They allow researchers to visualize similarities, dissimilarities, and ecological or biological gradients in a low-dimensional space—typically two or three dimensions.
Ordination techniques are widely applied in ecology, microbiome studies, epidemiology, genetics, environmental health, and clinical research. This article provides a comprehensive overview of ordination techniques in biostatistics, explaining their concepts, classifications, commonly used methods, interpretation strategies, and real-world applications.
What Are Ordination Techniques?
Ordination techniques are multivariate exploratory data analysis methods that arrange samples, species, or variables along continuous axes based on their relationships. The goal is to summarize complex datasets into a smaller number of synthetic variables (ordination axes) that capture the major sources of variation.
In simple terms, ordination:
- Reduces dimensionality
- Reveals hidden structures or gradients
- Helps visualize multivariate relationships
- Assists in hypothesis generation
Ordination results are commonly presented as scatter plots, where points represent samples, species, or variables positioned according to their similarity.
Why Ordination Is Important in Biostatistics
Ordination techniques are valuable because they:
- Handle multiple correlated variables simultaneously
- Identify patterns and clusters in biological data
- Detect environmental or clinical gradients
- Reduce noise and redundancy
- Complement hypothesis-testing methods
In biostatistics, ordination is often used as a preliminary exploratory step before advanced modeling or inferential analysis.
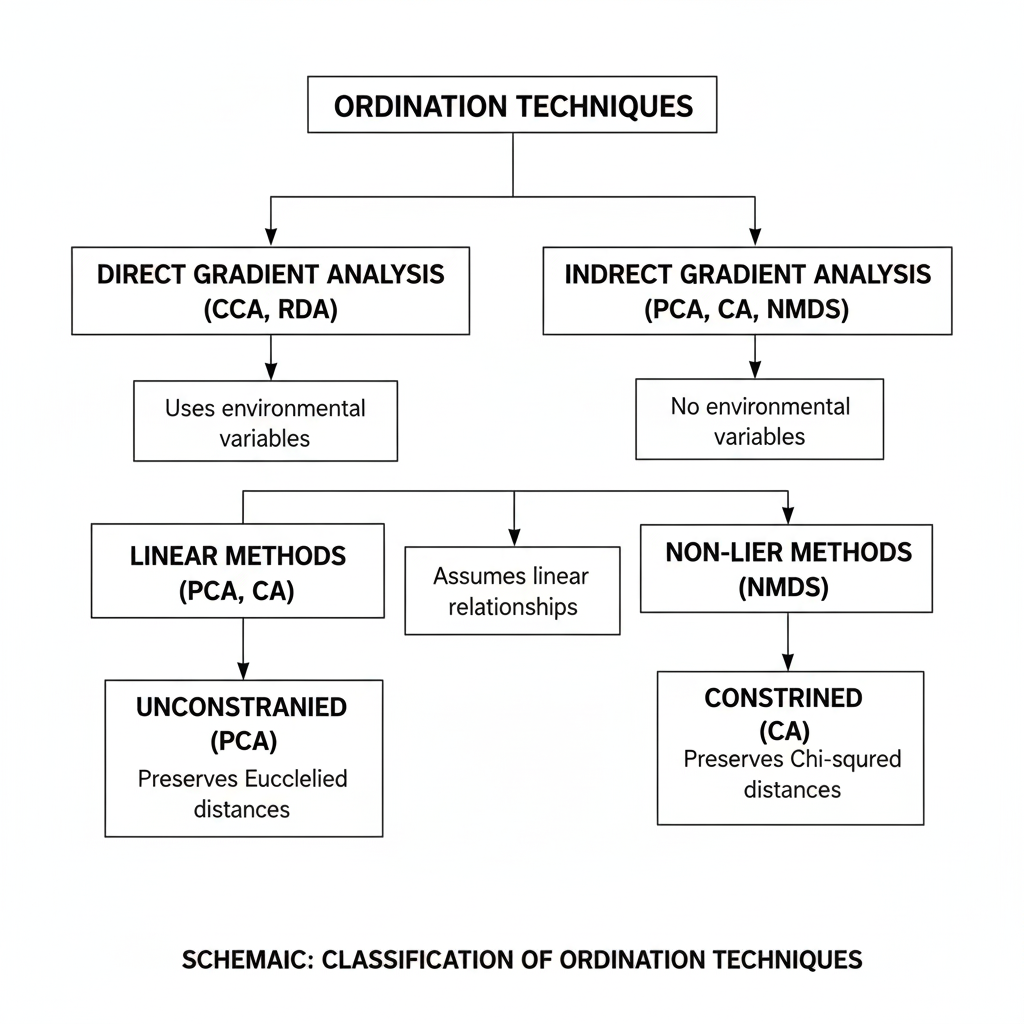
Classification of Ordination Techniques
Ordination techniques can be broadly classified into two main categories:
- Unconstrained Ordination
- Constrained Ordination
1. Unconstrained Ordination
Unconstrained ordination explores patterns without using external explanatory variables. The structure emerges purely from the data itself.
Common methods include:
- Principal Component Analysis (PCA)
- Principal Coordinates Analysis (PCoA)
- Correspondence Analysis (CA)
- Non-metric Multidimensional Scaling (NMDS)
2. Constrained Ordination
Constrained ordination incorporates external variables (e.g., environmental or clinical factors) to explain variation in the response data.
Common methods include:
- Canonical Correspondence Analysis (CCA)
- Redundancy Analysis (RDA)
- Distance-based Redundancy Analysis (db-RDA)
Common Ordination Techniques in Biostatistics
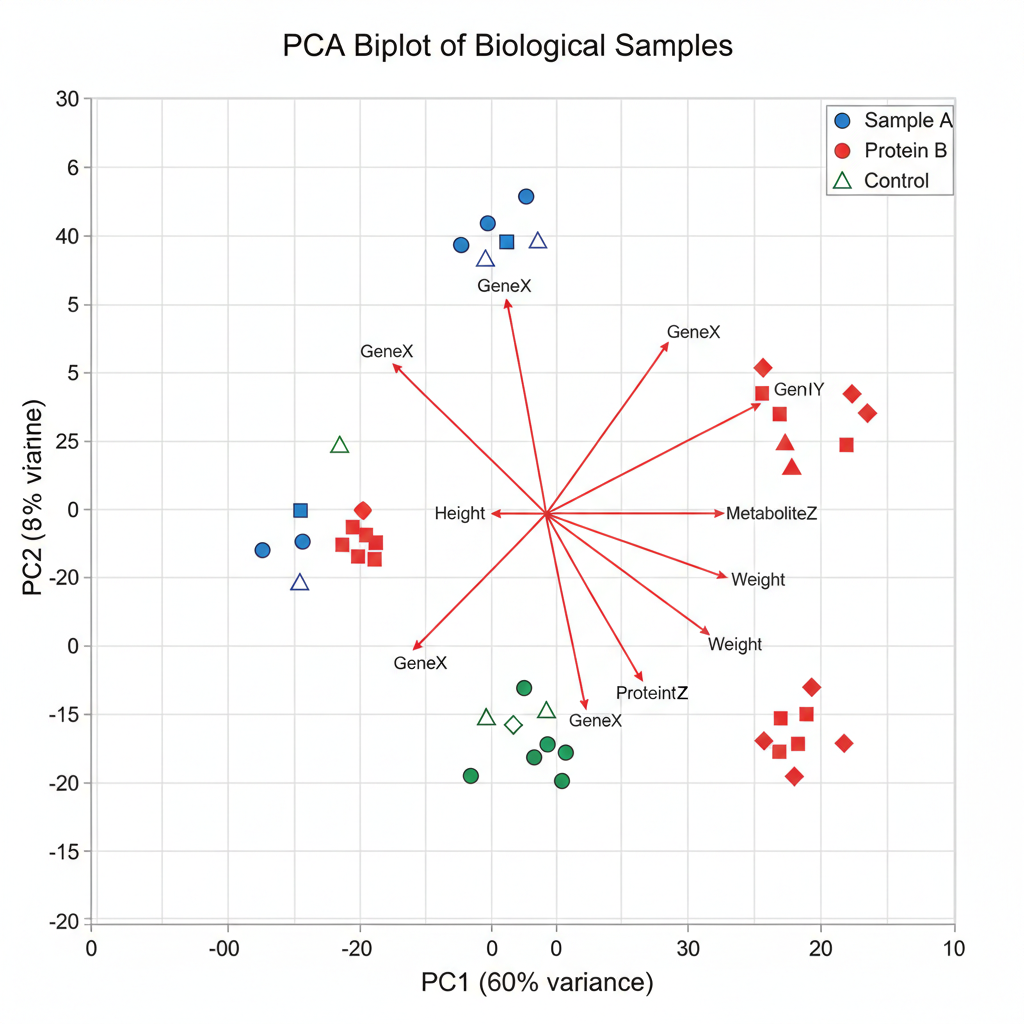
Principal Component Analysis (PCA)
PCA is one of the most widely used ordination techniques in biostatistics. It transforms correlated variables into a set of uncorrelated principal components, ordered by the amount of variance they explain.
Key features:
- Based on covariance or correlation matrix
- Assumes linear relationships
- Best for continuous, normally distributed data
Applications:
- Gene expression analysis
- Clinical biomarker studies
- Morphometric measurements
Principal Coordinates Analysis (PCoA)
PCoA is a distance-based ordination method that works with any dissimilarity matrix, such as Bray–Curtis or Jaccard distance.
Key features:
- Flexible distance measures
- Common in microbiome and ecological studies
- Handles non-Euclidean data
Applications:
- Microbial community analysis
- Beta diversity studies
- Ecological distance comparisons
Correspondence Analysis (CA)
CA is designed for count or abundance data, particularly species-by-site matrices.
Key features:
- Suitable for categorical and count data
- Reveals species–site associations
- Sensitive to rare species
Applications:
- Community ecology
- Species distribution studies
- Epidemiological contingency tables
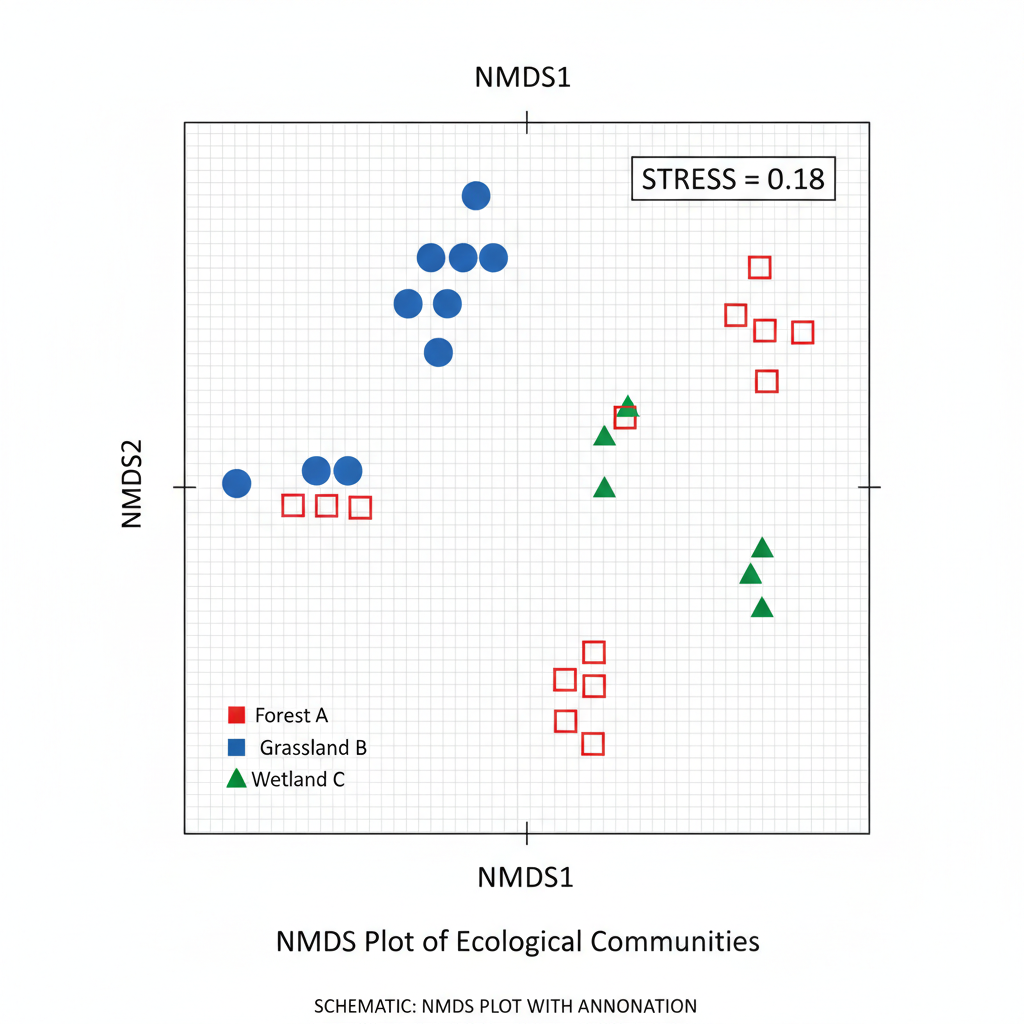
Non-metric Multidimensional Scaling (NMDS)
NMDS is a rank-based ordination technique that focuses on preserving relative dissimilarities, rather than exact distances.
Key features:
- Non-parametric
- Works with non-linear relationships
- Uses stress value to assess goodness of fit
Applications:
- Ecological community data
- Behavioral and social science data
- Microbiome research
Canonical Correspondence Analysis (CCA)
CCA is a constrained ordination method that relates species data directly to environmental or clinical variables.
Key features:
- Assumes unimodal species response
- Explains variation using predictors
- Useful for hypothesis testing
Applications:
- Environmental health studies
- Ecological impact assessment
- Disease–environment relationships
Redundancy Analysis (RDA)
RDA is a constrained version of PCA and assumes linear relationships between response and explanatory variables.
Key features:
- Combines regression and ordination
- Suitable for continuous predictors
- Easier interpretation than CCA
Applications:
- Environmental epidemiology
- Clinical multivariate modeling
- Experimental biology
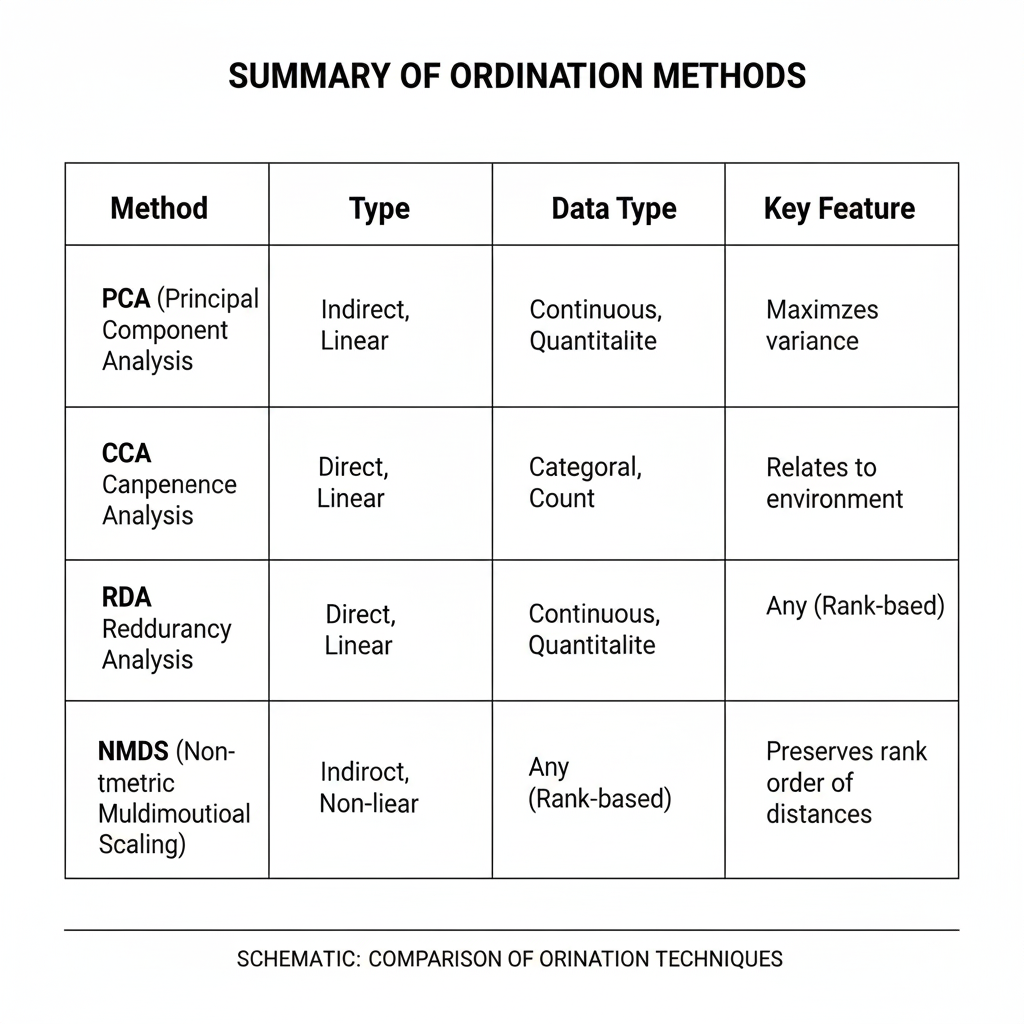
Comparison of Major Ordination Techniques
| Technique | Data Type | Assumptions | Constrained | Common Use |
|---|---|---|---|---|
| PCA | Continuous | Linear | No | Biomarkers, genetics |
| PCoA | Distance matrix | Distance-based | No | Microbiome studies |
| CA | Count data | Unimodal | No | Species abundance |
| NMDS | Any | Rank-based | No | Ecological communities |
| CCA | Species + predictors | Unimodal | Yes | Environment–species |
| RDA | Continuous + predictors | Linear | Yes | Multivariate regression |
Interpretation of Ordination Plots
Correct interpretation is essential for meaningful conclusions:
- Points close together indicate similarity
- Axes represent gradients or major sources of variation
- Eigenvalues or variance explained indicate axis importance
- Vectors show direction and strength of variable influence
- Stress value (NMDS) < 0.2 indicates acceptable fit
Ordination should always be interpreted in conjunction with biological or clinical knowledge.
Applications of Ordination in Biostatistics
Ordination techniques are applied across multiple domains:
- Ecology: Community structure and biodiversity
- Public Health: Disease clustering and exposure patterns
- Microbiology: Microbial diversity analysis
- Genomics: Gene expression profiling
- Environmental Science: Pollution and health impact studies
- Clinical Research: Multivariate patient stratification
Advantages and Limitations
Advantages
- Visualizes complex multivariate data
- Reduces dimensionality effectively
- Identifies hidden patterns
- Flexible across disciplines
Limitations
- Sensitive to data preprocessing
- Risk of over-interpretation
- Some methods assume linearity or unimodality
- Exploratory rather than confirmatory
Conclusion
Ordination techniques are indispensable tools in biostatistics for exploring, visualizing, and interpreting complex multivariate data. By reducing dimensionality and highlighting key patterns, these methods help researchers uncover meaningful biological, ecological, and clinical relationships that may otherwise remain hidden.
Selecting the appropriate ordination method depends on data type, research objectives, and underlying assumptions. When combined with sound statistical reasoning and domain expertise, ordination techniques significantly enhance data interpretation and scientific insight.
As biostatistical datasets continue to grow in size and complexity, ordination methods will remain central to exploratory data analysis in biological and health sciences.